Database 23ai : Principales fonctionnalités
Découvrez comment Oracle Database 23ai apporte l'IA à vos données, ce qui facilite le développement d'applications et les workloads critiques avec l'IA.
Chaque semaine, nous présenterons une nouvelle fonctionnalité d'Oracle Database 23ai avec des exemples afin que vous puissiez vous lancer rapidement. Enregistrez cette page et revenez chaque semaine pour voir les nouvelles fonctionnalités mises en avant.


Shrink Tablespace
Cette fonctionnalité vous permet de réduire les coûts et d'optimiser le stockage en vous permettant de réduire un tablespace de grande taille afin de récupérer l'espace inutilisé dans la base de données. Shrink Tablespace vous permet de réduire de manière fiable la taille d'un tablespace de grande taille afin de mieux vous adapter à la taille réelle des objets qu'il contient.
Fonctionnalités précédemment mises en avant
-

Transparent Application Continuity protège les applications C/C++, Java, .NET, Python et Node.js des pannes des couches logicielles, matérielles, de communication et de stockage sous-jacentes...
-

Si une transaction n'est pas validée (commit) ou annulée (rollback) pendant une longue période lorsqu'elle contient des verrous de ligne, elle peut potentiellement bloquer d'autres transactions de priorité élevée...
-

DBMS_SEARCH implémente la recherche omniprésente Oracle Text. DBMS_SEARCH facilite la création d'un index unique sur plusieurs tables et vues...
-

Nous avons ajouté des améliorations à Memoptimized Rowstore Fast Ingest avec la prise en charge du partitionnement, des tables compressées, du vidage rapide à l'aide d'écritures directes et de la prise en charge directe de la population de magasins de colonnes en mémoire...
-

Oracle Globally Distributed Database a introduit la fonctionnalité de réplication Raft dans Oracle Database 23c. Cela nous permet de réaliser un basculement très rapide (moins de 3 secondes) sans perte de données en cas de panne d'un nœud ou d'un data center...
-

SQL Plan Management (SPM) en temps réel détecte et répare rapidement les problèmes de performances SQL occasionnés par les modifications de plan d'exécution...
-

Cette semaine, nous mettons l'accent sur SQL Analysis Report, une fonctionnalité facile à utiliser qui aide les développeurs à écrire de meilleures instructions SQL...
-

True Cache (TC) est un cache en mémoire, cohérent et géré automatiquement pour Oracle Database. Il fonctionne de la même manière qu'un groupe de lecteurs Oracle Active Data Guard, sauf que les instances True Cache sont principalement sans disque et conçues pour les performances et l'évolutivité, contrairement à la reprise après sinistre...
Disponibilité de l'application : aucun temps d'inactivité pour les clients de base de données

La continuité d'application transparente protège les applications C/C++, Java, .NET, Python et Node.js des pannes des couches logicielles, matérielles, de communication et de stockage sous-jacentes. Avec Oracle Real Application Clusters (RAC), Active Data Guard (ADG) et Autonomous Database (Shared and Dedicated), Oracle Database reste accessible même en cas de défaillance d'un nœud ou d'un sous-ensemble du cluster RAC ou de mise hors ligne à des fins de maintenance.
Oracle Database 23c apporte de nombreuses améliorations, notamment la prise en charge des applications de traitement par lots, par exemple les curseurs ouverts, également appelés curseurs stables d'état de session.
Blogs
Annulation automatique des transactions

Si une transaction n'est pas validée (commit) ou annulée (rollback) pendant une longue période alors qu'elle contient des verrous de ligne, elle peut potentiellement bloquer d'autres transactions de priorité élevée. Cette fonctionnalité permet aux applications d'affecter des priorités aux transactions et aux administrateurs de définir des délais d'attente pour chaque priorité. La base de données annule automatiquement une transaction de priorité inférieure et libère les verrous de ligne conservés si elle bloque une transaction de priorité supérieure au-delà du délai défini, ce qui permet à la transaction de priorité supérieure de continuer.
L'annulation automatique des transactions réduit la charge de gestion tout en aidant à maintenir les latences/contrats de niveau de service des transactions de priorité supérieure.
Blogs
Documentation
DBMS_Search

DBMS_SEARCH implémente la recherche omniprésente Oracle Text. DBMS_SEARCH facilite la création d'un index unique sur plusieurs tables et vues. Créez simplement un index DBMS_SEARCH et ajoutez des tables et des vues. Toutes les valeurs pouvant faire l'objet d'une recherche, y compris les colonnes VARCHAR, CLOB, JSON et numériques, sont incluses dans l'index, qui est automatiquement tenu à jour lorsque le contenu de la table ou de la vue change.
Améliorations de Fast Ingest

Nous avons ajouté des améliorations à Memoptimized Rowstore Fast Ingest avec la prise en charge du partitionnement, des tables compressées, du vidage rapide à l'aide d'écritures directes et de la prise en charge directe de la population de magasins de colonnes en mémoire. Grâce à ces améliorations, la fonctionnalité d'inclusion rapide est plus facile à intégrer dans les situations où l'ingestion rapide de données est requise. Oracle Database fournit désormais une meilleure prise en charge des applications nécessitant des fonctionnalités d'ingestion rapide des données. Les données peuvent toutes être ingérées, puis traitées dans la même base de données. Cela réduit le besoin d'environnements de chargement spéciaux et réduit ainsi la complexité et la redondance des données.
Réplication basée sur Raft dans Globally Distributed Database

Oracle Globally Distributed Database a introduit la fonctionnalité de réplication Raft dans Oracle Database 23c. Cela nous permet de réaliser un basculement très rapide (moins de 3 secondes) sans perte de données en cas de panne d'un nœud ou d'un centre de données. La réplication Raft utilise un protocole de validation basé sur le consensus et est configurée de manière déclarative en spécifiant le facteur de réplication. Tous les shards d'une base de données distribuée agissent en tant que nœuds principaux et secondaires pour un sous-ensemble de données. Cela permet une architecture de base de données distribuée symétrique active/active/active où tous les shards servent le trafic de l'application.
Cette configuration permet d'améliorer la disponibilité sans perte de données, de simplifier la gestion et d'optimiser l'utilisation du matériel pour les environnements de bases de données distribuées à l'échelle mondiale.
SQL Plan Management en temps réel

SQL Plan Management (SPM) en temps réel détecte et répare rapidement les problèmes de performances SQL occasionnés par les modifications de plan d'exécution.
Si une instruction SQL s'exécute correctement, mais qu'une modification de plan entraîne une mauvaise exécution, le module SPM en temps réel la détecte immédiatement. S'il établit qu'un plan précédent fonctionnera mieux, le module SPM en temps réel le rétablit à l'aide d'un plan SQL de référence.
Cela automatise ce que certains administrateurs de base de données font déjà : ils créent des plan SQL de référence pour cibler les instructions SQL individuelles présentant des problèmes de performances intermittents et appliquent un plan dont la fiabilité est connue.
Rapport d'analyse SQL

Cette semaine, nous mettons l'accent sur SQL Analysis Report, une fonctionnalité facile à utiliser qui aide les développeurs à écrire de meilleures instructions SQL. Le rapport d'analyse SQL signale les problèmes courants liés aux instructions SQL, en particulier ceux qui peuvent entraîner des performances SQL médiocres. Il est disponible dans DBMS_XPLAN et SQL Monitor.
Documentation
True Cache

True Cache (TC) est un cache en mémoire, cohérent et géré automatiquement pour Oracle Database. Il fonctionne de la même manière qu'un groupe de lecteurs Oracle Active Data Guard, sauf que les instances True Cache sont principalement sans disque et conçues pour les performances et l'évolutivité, contrairement à la reprise après sinistre. Une application peut se connecter directement aux instances True Cache pour les charges de travail en lecture seule. Une application Java générale en lecture/écriture peut également marquer simplement certaines sections de code en lecture seule, et le pilote JDBC True Cache d'Oracle Database 23ai peut envoyer automatiquement des charges de travail en lecture seule aux instances True Cache configurées.
Aujourd'hui, de nombreux utilisateurs d'Oracle placent un cache devant Oracle Database pour accélérer les temps de réponse aux requêtes et améliorer l'évolutivité en général. True Cache est un nouveau moyen de disposer d'un cache en amont d'Oracle Database. True Cache présente de nombreux avantages : facilité d'utilisation, données cohérentes, données plus récentes et gestion automatique du cache.
-

La blockchain et les tables immuables, disponibles depuis la sortie d'Oracle Database 19c, utilisent des méthodes de chiffrement sécurisées pour protéger les données contre les altérations ou les suppressions par des pirates externes et des personnes malveillantes ou compromises...
-

Oracle Database 23ai introduit une nouvelle fonctionnalité d'audit unifié permettant une sélection au niveau des colonnes en vue de créer des règles d'audit plus ciblées qui réduisent le « bruit » occasionné par les enregistrements d'audit inutiles.
-

Oracle Database 23c inclut le nouveau rôle DB_DEVELOPER_ROLE, qui fournit à un développeur d'applications tous les privilèges nécessaires pour concevoir, implémenter, déboguer et déployer des applications sur des bases de données Oracle...
-

Oracle Database prend désormais en charge les privilèges de schéma en plus des privilèges d'objet, de système et d'administration existants...
-
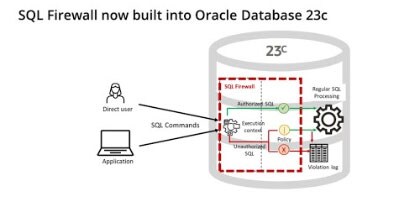
Utilisez SQL Firewall pour détecter les anomalies et empêcher les injections SQL. SQL Firewall examine toutes les instructions SQL, y compris les informations de contexte de session telles que l'adresse IP et l'utilisateur du système d'exploitation...
Tables blockchain

La blockchain et les tables immuables, disponibles depuis la sortie d'Oracle Database 19c, utilisent des méthodes de chiffrement sécurisées pour protéger les données contre les altérations ou les suppressions par des pirates externes et des personnes malveillantes ou compromises. Cela inclut les restrictions d'insertion uniquement qui empêchent les mises à jour ou les suppressions (même par les administrateurs de base de données), les chaînes de hachage cryptographiques pour permettre la vérification, les synthèses de table signées pour détecter les rétractactions à grande échelle et la signature par l'utilisateur final des lignes insérées à l'aide de leurs clés privées. Oracle Database 23c apporte de nombreuses améliorations, notamment la prise en charge de la réplication logique via Oracle GoldenGate et des mises à niveau non simultanées à l'aide d'Active Data Guard, la prise en charge des transactions distribuées impliquant des tables de blockchain, une suppression en masse efficace reposant sur des partitions pour les lignes expirées et des optimisations des performances pour les insertions/validations.
Cette version offre également la possibilité d'ajouter ou de supprimer des colonnes sans affecter le chaînage de hachage cryptographique, les chaînes spécifiques à l'utilisateur et les synthèses de table pour les lignes filtrées, la capacité de signature déléguée et la contresignature de base de données. Elle étend également la gestion des données protégées par chiffrement aux tables standard en permettant un audit des modifications historiques apportées à une table sans blockchain via l'archive Flashback définie pour utiliser une table d'historique de blockchain.
Idéales pour les cas d'utilisation de piste d'audit ou de journalisation intégrés, ces fonctionnalités peuvent être utilisées pour les livres financiers, l'historique des paiements, le suivi de la conformité réglementée, les journaux légaux et toutes les données représentant des actifs pour lesquels la falsification ou la suppression peut entraîner des conséquences juridiques, financières ou de réputation importantes.
Vidéos
- Tables blockchain dans Oracle Database 21c (4:15)
- Bases de données en mémoire et tables de blockchain (55:42)
Articles
- Récupération d'espace inutilisé dans Oracle Database 23c avec 'tablespace_shrink'
- Améliorations apportées aux tables de blockchain dans Oracle Database 23c
- Améliorations apportées aux tables immuables dans Oracle Database 23c
- Pourquoi Oracle a-t-il implémenté la blockchain dans Oracle Database 23c ?
Audit au niveau des colonnes

Oracle Database 23ai introduit une nouvelle fonctionnalité d'audit unifié permettant une sélection au niveau des colonnes en vue de créer des règles d'audit plus ciblées qui réduisent le « bruit » occasionné par les enregistrements d'audit inutiles.
Vidéo
Blogs
Privilèges de schéma

Oracle Database prend désormais en charge les privilèges de schéma en plus des privilèges d'objet, de système et d'administration existants. Cette fonctionnalité améliore la sécurité en simplifiant l'autorisation pour les objets de base de données afin de mieux implémenter le principe du moindre privilège et de déterminer avec précision les accès.
Vidéos
- La sécurité devient tellement SIMPLE avec la version 23c ! (3:55)
- Une gestion de la sécurité beaucoup plus simple avec la version 23c (1:18)
Blogs
Exemple de code
Documentation
SQL Firewall
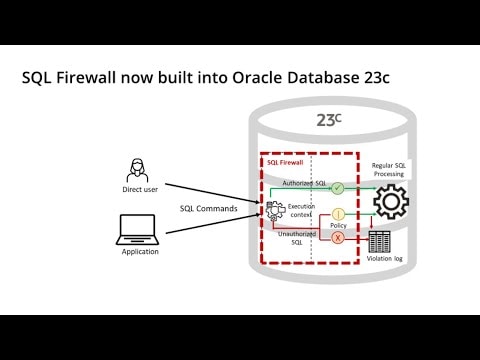
Utilisez SQL Firewall pour détecter les anomalies et empêcher les injections SQL. SQL Firewall examine toutes les instructions SQL, y compris les informations de contexte de session telles que l'adresse IP et l'utilisateur du système d'exploitation. Intégré dans le noyau de base de données, SQL Firewall écrit des journaux et (s'il est activé) bloque les instructions SQL non autorisées, pour éviter les contournements. En appliquant une liste d'autorisation de contextes de session SQL et approuvés, SQL Firewall peut empêcher de nombreuses attaques zero-day et réduire le risque de vol de données d'identifications.
Blogs
Articles
- Nouvelle fonctionnalité d'Oracle Database 23c : SQL Firewall avec le Directeur ACE, Gavin Soorma
- Les trois nouveaux packages PL/SQL dans Oracle Database 23c par Julian Dontcheff, Directeur ACE
- SQL Firewall dans Oracle Database 23c par Tim Hall, Directeur ACE
- SQL Firewall, Oracle Database 23c par Pete Finnigan, expert en sécurité de base de données : Partie 1, Partie 2, Partie 3
Tutoriels pratiques
Documentation
DB_DEVELOPER_ROLE

Oracle Database 23c inclut le nouveau rôle DB_DEVELOPER_ROLE, qui fournit à un développeur d'applications tous les privilèges nécessaires pour concevoir, implémenter, déboguer et déployer des applications sur des bases de données Oracle. Grâce à ce rôle, les administrateurs n'ont plus à deviner les privilèges nécessaires pour le développement d'applications.
-

Oracle Database prend désormais en charge le type de données booléen conforme à la norme ISO SQL. Vous pouvez ainsi stocker des valeurs True et False dans des tables et utiliser des expressions booléennes dans des instructions SQL...
-

Oracle Database vous permet désormais de joindre la table cible dans les instructions UPDATE et DELETE à d'autres tables à l'aide de la clause FROM. Ces autres tables peuvent limiter les lignes modifiées ou être la source de nouvelles valeurs...
-

Vous pouvez désormais utiliser un alias de colonne ou une position d'élément SELECT dans les clauses GROUP BY, GROUP BY CUBE, GROUP BY ROLLUP et GROUP BY GROUPING SETS. En outre, la clause HAVING prend en charge les alias de colonne...
-

La création, la modification et la suppression d'objets DDL dans Oracle Database prennent désormais en charge les modificateurs de syntaxe IF EXISTS et IF NOT EXISTS...
-

Oracle Database 23c permet aux développeurs de calculer plus facilement les totaux et les moyennes sur des valeurs INTERVAL...
-

La clause RETURNING INTO pour les instructions INSERT, UPDATE et DELETE a été améliorée pour signaler les anciennes et les nouvelles valeurs affectées par l'instruction correspondante...
-
Vous pouvez désormais exécuter des requêtes uniquement avec l'expression SELECT sans la clause FROM. Cette nouvelle fonctionnalité améliore la portabilité du code SQL et sa facilité d'utilisation pour les développeurs.
-

Créez des macros SQL pour intégrer les expressions et instructions SQL courantes dans des structures paramétrées réutilisables pouvant être utilisées dans d'autres instructions SQL...
-

Les fonctions PL/SQL dans les instructions SQL sont automatiquement converties (transpilées) en expressions SQL chaque fois que cela est possible...
-

Le moteur SQL Oracle Database prend désormais en charge une clause VALUES pour de nombreux types d'instruction...
-

Les annotations permettent de stocker et d'extraire des métadonnées sur les objets de base de données. Il s'agit de champs de texte de forme libre que les applications peuvent utiliser pour personnaliser la logique métier ou les interfaces utilisateur...
-

Les domaines d'utilisation (parfois appelés domaines SQL ou domaines d'utilisation d'application) sont des objets de dictionnaire de haut niveau qui agissent en tant que modificateurs de type légers et documentent de manière centralisée l'utilisation prévue des données pour les applications...
-

Vous pouvez désormais stocker un plus grand nombre d'attributs sur une seule ligne, ce qui peut simplifier la conception et l'implémentation de certaines applications...
Type de données booléennes

Oracle Database prend désormais en charge le type de données booléen conforme à la norme ISO SQL. Vous pouvez ainsi stocker des valeurs True et False dans des tables et utiliser des expressions booléennes dans des instructions SQL. Le type de données booléen standardise le stockage des valeurs « oui » et « non » et facilite la migration vers Oracle Database.
Jointures directes pour les instructions UPDATE et DELETE

Oracle Database vous permet désormais de joindre la table cible dans les instructions UPDATE et DELETE à d'autres tables à l'aide de la clause FROM. Ces autres tables peuvent limiter les lignes modifiées ou être la source de nouvelles valeurs. Les jointures directes facilitent l'écriture de code SQL pour modifier et supprimer des données.
Blogs
Articles
Alias de colonne GROUP BY

Vous pouvez désormais utiliser un alias de colonne ou une position d'élément SELECT dans les clauses GROUP BY, GROUP BY CUBE, GROUP BY ROLLUP et GROUP BY GROUPING SETS. En outre, la clause HAVING prend en charge les alias de colonne. Ces nouvelles améliorations apportées par Database 23c facilitent l'écriture des clauses GROUP BY et HAVING, ce qui rend les requêtes SQL beaucoup plus lisibles et maintenables tout en offrant une meilleure portabilité du code SQL.
IF [NOT] EXISTS

La création, la modification et la suppression d'objets DDL dans Oracle Database prennent désormais en charge les modificateurs de syntaxe IF EXISTS et IF NOT EXISTS. Cela vous permet de contrôler la nécessité de signaler une erreur si un objet donné existe ou n'existe pas, ce qui simplifie la gestion des erreurs dans les scripts et par les applications.
Vidéos
Blogs
Groupements de types de données INTERVAL

Oracle Database 23c permet aux développeurs de calculer plus facilement les totaux et les moyennes sur des valeurs INTERVAL. Grâce à cette amélioration, vous pouvez désormais transmettre les types de données INTERVAL aux fonctions d'agrégation et d'analyse SUM et AVG.
Clause RETURNING INTO

La clause RETURNING INTO pour les instructions INSERT, UPDATE et DELETE a été améliorée pour signaler les anciennes et les nouvelles valeurs affectées par l'instruction correspondante. Cela permet aux développeurs d'utiliser la même logique pour chacun de ces types DML afin d'obtenir des valeurs avant et après l'exécution de l'instruction. Les anciennes et les nouvelles valeurs ne sont valides que pour les instructions UPDATE. Les instructions INSERT ne retournent pas d'anciennes valeurs et les instructions DELETE ne retournent pas de nouvelles valeurs.
La possibilité d'obtenir les anciennes et les nouvelles valeurs affectées par les instructions INSERT, UPDATE et DELETE dans le cadre de l'exécution de la commande SQL offre aux développeurs une approche uniforme pour la lecture de ces valeurs et réduit la quantité de travail que la base de données doit effectuer.
SELECT sans la clause FROM
Vous pouvez désormais exécuter des requêtes uniquement avec l'expression SELECT sans la clause FROM. Cette nouvelle fonctionnalité améliore la portabilité du code SQL et sa facilité d'utilisation pour les développeurs.
Macros SQL

Créez des macros SQL pour intégrer les expressions et instructions SQL courantes dans des structures paramétrées réutilisables pouvant être utilisées dans d'autres instructions SQL. Les macros SQL peuvent être des expressions scalaires généralement utilisées dans les listes SELECT, ainsi que dans les clauses WHERE, GROUP BY et HAVING. Les macros SQL peuvent également être utilisées pour encapsuler des calculs et une logique métier, ou peuvent être des expressions de table, généralement utilisées dans une clause FROM. Par rapport aux structures PL/SQL, les macros SQL peuvent améliorer les performances. Les macros SQL augmentent la productivité des développeurs, simplifient le développement collaboratif et améliorent la qualité du code.
Transpilateur SQL

Les fonctions PL/SQL des instructions SQL sont automatiquement converties (transpilées) en expressions SQL chaque fois que cela est possible. La transposition de fonctions PL/SQL en instructions SQL peut réduire le temps d'exécution global.
Constructeur de valeur de table

Le moteur SQL Oracle Database prend désormais en charge une clause VALUES pour de nombreux types d'instruction. Cela vous permet de matérialiser des lignes de données à la volée en les spécifiant à l'aide de la nouvelle syntaxe sans dépendre des tables existantes. Oracle Database 23c prend en charge la clause VALUES pour les instructions SELECT, INSERT et MERGE. L'introduction de la nouvelle clause VALUES permet aux développeurs d'écrire moins de code pour les commandes SQL ponctuelles, ce qui permet une meilleure lisibilité avec moins d'effort.
Vidéos
Blogs
Annotations d'utilisation

Les annotations permettent de stocker et d'extraire des métadonnées sur les objets de base de données. Il s'agit de champs de texte de forme libre que les applications peuvent utiliser pour personnaliser la logique métier ou les interfaces utilisateur. Les annotations sont des paires nom-valeur ou simplement un nom. Ils vous aident à utiliser les objets de base de données de la même manière dans toutes les applications, ce qui simplifie le développement et améliore la qualité des données.
Domaines d'utilisation

Les domaines d'utilisation (parfois appelés domaines SQL ou domaines d'utilisation d'application) sont des objets de dictionnaire de haut niveau qui agissent en tant que modificateurs de type légers et documentent de manière centralisée l'utilisation prévue des données pour les applications. Les domaines d'utilisation peuvent être utilisés pour définir l'utilisation des données et standardiser les opérations afin d'encapsuler un ensemble de contraintes de vérification, de propriétés d'affichage, de règles de tri et d'autres propriétés d'utilisation, sans nécessiter de métadonnées au niveau de l'application.
Les domaines d'utilisation d'une ou de plusieurs colonnes d'une table ne modifient pas le type de données sous-jacent et peuvent donc également être ajoutés aux données existantes sans interrompre les applications ou engendrer des problèmes de portabilité.
Larges tables avec désormais jusqu'à 4 096 colonnes

Vous pouvez désormais stocker un plus grand nombre d'attributs sur une seule ligne, ce qui peut simplifier la conception et l'implémentation de certaines applications.
Le nombre maximal de colonnes autorisées dans une table ou une vue de base de données a été porté à 4 096. Cette fonctionnalité dépasse la limite précédente de 1 000 colonnes, ce qui vous permet de créer des applications pouvant stocker des attributs dans une seule table. Certaines applications telles que le machine learning et la transmission en continu des workloads des applications d'Internet des objets (IoT) peuvent nécessiter l'utilisation de tables dénormalisées avec plus de 1 000 colonnes.
-

Oracle Database 23c et CMAN-TDM offrent désormais des fonctionnalités de gestion et de surveillance des connexions de pointe avec un pool de connexions implicite, un DRCP multi-pool, un PRCP par base de données enfichable et bien plus encore...
-

Avec Oracle Database 23c, la fonctionnalité de pipelining permet aux applications .NET, Java et C/C++ d'envoyer plusieurs requêtes à la base de données sans attendre la réponse du serveur...
-

Les appels de module de moteur multilingue (MLE) permettent aux développeurs d'appeler des fonctions JavaScript stockées dans des modules à partir de SQL et PL/SQL. Appelez les spécifications écrites dans le lien PL/SQL JavaScript vers les unités de code PL/SQL...
-

Une nouvelle fonctionnalité d'Oracle Database 23ai est la capacité du client à stocker des informations de configuration Oracle, telles que des chaînes de connexion, dans Microsoft Azure App Configuration ou Oracle Cloud Infrastructure Object Storage...
-

Les trois piliers de l'observabilité sont les mesures, la journalisation et le traçage distribué. Cette version apporte une journalisation améliorée, un nouveau débogage (diagnostic lors du premier échec) et de nouvelles fonctionnalités de traçage...
-

Oracle Database 23c introduit Transportable Binary XML (TBX), une nouvelle méthode de stockage autonome de XMLType. TBX prend en charge le sharding, l'index de recherche XML et les opérations de propagation Exadata, offrant de meilleures performances et une meilleure évolutivité que les autres options de stockage XML...
Gestion des connexions pour une évolutivité extrême

Oracle Database 23c et CMAN-TDM offrent désormais des fonctionnalités de gestion et de surveillance des connexions de pointe avec un pool de connexions implicite, un DRCP multi-pool, un PRCP par base de données enfichable et bien plus encore. Améliorez l'évolutivité et la puissance de vos applications C, Java, Python, Node.js et ODP.NET avec les fonctionnalités les plus récentes et les plus performantes de DRCP et PRCP. Surveillez efficacement l'utilisation du pool PRCP à l'aide des statistiques de la nouvelle vue dynamique V$TDM_STATS d'Oracle Database 23c.
Blogs
Programmation asynchrone des pilotes de base de données et pipelining

Avec Oracle Database 23c, la fonctionnalité de pipelining permet aux applications .NET, Java et C/C++ d'envoyer plusieurs requêtes à la base de données sans attendre la réponse du serveur. Oracle Database met en file d'attente et traite ces demandes une par une, ce qui permet aux applications client de continuer à travailler jusqu'à la notification de la fin des requêtes. Ces améliorations offrent une meilleure expérience à l'utilisateur final, une meilleure réactivité des applications basées sur les données, une évolutivité de bout en bout, l'évitement des goulets d'étranglement des performances et une utilisation efficace des ressources côté serveur et côté client.
Pour que la requête du client soit renvoyée immédiatement, Oracle Database Pipelining nécessite une API asynchrone ou réactive dans les pilotes .NET, Java et C/C++. Ces mécanismes peuvent être utilisés sur Oracle Database, avec ou sans Database Pipelining.
Pour Java, Oracle Database 23c fournit les extensions réactives dans JDBC (Java Database Connectivity), UCP (Universal Connection Pool) et le pilote Oracle R2DBC. Il prend également en charge les threads virtuels Java dans le pilote du Project Loom ainsi que les bibliothèques Reactive Streams, telles que Reactor, RxJava, Akka Streams, Vert.x, etc.
Blogs
Articles
Procédures stockées JavaScript

Les appels de module de moteur multilingue (MLE) permettent aux développeurs d'appeler des fonctions JavaScript stockées dans des modules à partir de SQL et PL/SQL. Appelez les spécifications écrites dans le lien PL/SQL JavaScript vers les unités de code PL/SQL. Cette fonctionnalité permet aux développeurs d'utiliser les fonctions JavaScript partout où les fonctions PL/SQL sont appelées.
Blogs
Configuration multicloud et intégration de la sécurité

Une nouvelle fonctionnalité d'Oracle Database 23ai est la capacité du client à stocker des informations de configuration Oracle, telles que des chaînes de connexion, dans Microsoft Azure App Configuration ou Oracle Cloud Infrastructure Object Storage. Cette nouvelle fonctionnalité simplifie la configuration, le déploiement et la connectivité du cloud d'application avec les pilotes d'accès aux données Oracle JDBC, .NET, Python, Node.js et Oracle Call Interface. Les informations sont stockées dans des fournisseurs de configuration, ce qui permet de séparer le code des applications et leur configuration.
Utilisez l'accès avec une connexion unique OAuth 2.0 au cloud et à la base de données pour faciliter encore davantage l'administration. Les clients Oracle Database 23c peuvent utiliser Microsoft Entra ID, Azure Active Directory ou des jetons d'accès Oracle Cloud Infrastructure pour la connexion à la base de données.
Blogs
Observabilité, OpenTelemetry et diagnostic pour les applications Java et .NET

Les trois piliers de l'observabilité sont les mesures, la journalisation et le traçage distribué. Cette version apporte une journalisation améliorée, un nouveau débogage (diagnostic lors du premier échec) et de nouvelles fonctionnalités de traçage. Les pilotes JDBC et ODP.NET ont également été équipés d'un hook pour le traçage des appels de base de données. Ce hook active la fonction de traçage distribué à l'aide d'OpenTelemetry.
Transportable Binary XML

Oracle Database 23c introduit Transportable Binary XML (TBX), une nouvelle méthode de stockage autonome de XMLType. TBX prend en charge le sharding, l'index de recherche XML et les opérations de propagation Exadata, offrant de meilleures performances et une meilleure évolutivité que les autres options de stockage XML.
Grâce à la prise en charge d'un plus grand nombre d'architectures de base de données, telles que le sharding ou Exadata, et à sa capacité à migrer et à échanger facilement des données XML entre différents serveurs, conteneurs et bases de données enfichables, TBX permet à vos applications de tirer pleinement parti de ce nouveau format de stockage XML sur davantage de plateformes et d'architectures.
Vous pouvez migrer le stockage XMLType existant d'un autre format vers le format TBX de l'une des manières suivantes :
Insert-as-select ou create-as-select
Redéfinition en ligne
Oracle Data Pump
-

Le type de données JSON est un format JSON binaire optimisé par Oracle appelé OSON. Il est conçu pour des performances d'interrogation et de DML plus rapides dans la base de données et dans les clients de base de données à partir de la version 21c et les versions supérieures...
-

La dualité relationnelle JSON, une innovation introduite dans Oracle Database 23c, unifie les modèles de données relationnelles et documentaires pour fournir le meilleur de ces deux approches...
-

Oracle Database prend en charge le format JSON pour stocker et traiter des données dans des schémas flexibles. Avec Oracle Database 23c, Oracle Database prend désormais en charge JSON Schema pour valider la structure et les valeurs des données JSON...
-

Avec l'API d'Oracle Database pour MongoDB, les développeurs peuvent continuer à utiliser les outils et pilotes de MongoDB connectés à Oracle Database tout en ayant accès aux fonctionnalités multimodèles et à la base de données à pilotage automatique d'Oracle...
-

Le constructeur PL/SQL JSON a été amélioré pour accepter une instance d'un type d'agrégation PL/SQL correspondant, renvoyant un objet JSON ou un type de tableau rempli avec les données de type d'agrégation.
Type de données binaire JSON

Le type de données JSON est un format JSON binaire optimisé par Oracle appelé OSON. Il est conçu pour des performances d'interrogation et de DML plus rapides dans la base de données et dans les clients de base de données à partir de la version 21c et les versions supérieures.
Vues avec la dualité relationnelle JSON

La dualité relationnelle JSON, une innovation introduite dans Oracle Database 23c, unifie les modèles de données relationnelles et documentaires pour fournir le meilleur de ces deux approches. Les développeurs peuvent créer des applications dans des paradigmes relationnels ou JSON avec une source unique d'informations fiables et tirer parti des atouts des deux modèles. Les données sont stockées une seule fois, mais sont accessibles, écrites et modifiées selon l'une ou l'autre approche. Les développeurs bénéficient de transactions et de contrôles de simultanéité ACID, ce qui signifie qu'ils n'ont plus à faire de compromis entre des correspondances objet-relationnel complexes ou des problèmes d'incohérence de données.
Articles
Blogs
Documentation
JSON Schema

Oracle Database prend en charge le format JSON pour stocker et traiter des données dans des schémas flexibles. Avec Oracle Database 23c, Oracle Database prend désormais en charge JSON Schema pour valider la structure et les valeurs des données JSON. L'opérateur SQL IS JSON a été amélioré pour accepter un schéma JSON et diverses fonctions PL/SQL ont été ajoutées pour valider les données JSON et pour décrire des objets de base de données tels que des tables, des vues et des types en tant que documents de schéma JSON.
Par défaut, les données JSON sont sans schéma, ce qui offre de la flexibilité. Cependant, vous pouvez vous assurer que les données JSON ont une structure particulière, ce qui peut être fait via la validation avec le standard JSON Schema.
Contribuer à JSON Schema
Oracle contribue activement au schéma JSON, un projet open source visant à standardiser un langage déclaratif basé sur JSON qui vous permet d'annoter et de valider des documents JSON. Son statut est actuellement en « Attente de commentaires » (RFC).
Prise en charge du constructeur PL/SQL JSON pour les types d'agrégat

Le constructeur PL/SQL JSON a été amélioré pour accepter une instance d'un type d'agrégation PL/SQL correspondant, renvoyant un objet JSON ou un type de tableau rempli avec les données de type d'agrégation.
L'opérateur PL/SQL JSON_VALUE est amélioré afin que sa clause de renvoi puisse accepter un nom de type qui définit le type de l'instance que l'opérateur doit renvoyer. La prise en charge des constructeurs JSON pour les types de données agrégées rationalise l'échange de données entre les applications PL/SQL et les langages prenant en charge JSON.
API compatible avec MongoDB

Avec l'API d'Oracle Database pour MongoDB, les développeurs peuvent continuer à utiliser les outils et pilotes de MongoDB connectés à Oracle Database tout en ayant accès aux fonctionnalités multimodèles et à la base de données à pilotage automatique d'Oracle. Les clients peuvent exécuter leurs workloads MongoDB sur Oracle Cloud Infrastructure (OCI). Souvent, les applications MongoDB existantes nécessitent peu de modifications, voire aucune. Il vous suffit de modifier la chaîne de connexion.
L'API Oracle Database pour MongoDB fait partie d'Oracle REST Data Services standard. Elle est préconfigurée et entièrement gérée dans le cadre d'Oracle Autonomous Database.
-

Oracle AI Vector Search est une nouvelle fonctionnalité de base de données convergée introduite dans Oracle Database 23ai. Elle utilise des vecteurs pour permettre des requêtes de recherche de similarité rapides et simples sur des données structurées et non structurées...
-

Oracle Database offre une prise en charge native des structures de données de graphe de propriétés et des requêtes de graphe...
Recherche de vecteur IA

Oracle AI Vector Search est une nouvelle fonctionnalité de base de données convergée introduite dans Oracle Database 23ai. Elle utilise des vecteurs pour permettre des requêtes de recherche de similarité rapides et simples sur des données structurées et non structurées. AI Vector Search permet également d'enrichir les invites des grands modèles de langage (LLM) au moyen de données commerciales privées ou de connaissances de domaine.
AI Vector Search stocke des vecteurs en tant que type de données natif et utilise des index vectoriels et des fonctions SQL pour exécuter une recherche de similarité sur les vecteurs. Avec cette fonctionnalité, les clients peuvent rapidement trouver des informations similaires à partir de documents, d'images et d'autres données non structurées.
AI Vector Search facilite la recherche rapide de données structurées et non structurées et combine ces résultats avec les résultats des requêtes de base de données traditionnelles. Les données source de pratiquement n'importe quel type et les vecteurs qui les représentent peuvent être stockés ensemble dans la même base de données, ce qui réduit la complexité et aide à maintenir la cohérence des données. La recherche de vecteur IA, combinée à la génération augmentée par extraction (RAG), aide les utilisateurs de LLM à obtenir des réponses plus précises et aide à réduire les hallucinations.
AI Vector Search permet aux développeurs d'ajouter et de conserver des fonctionnalités de recherche de similarité aux applications et bases de données existantes ou d'en créer de nouvelles. Deux cas d'utilisation s'appliquent à presque tous les secteurs d'activité. Parce que tous les clients recherchent la simplicité, Oracle propose l'IA/ML sans avoir besoin d'un PhD en data science.
- Recherches de similarité : recherche de contenu similaire dans des données non structurées (texte, audio, images, vidéo, etc.). Les données non structurées peuvent être des fichiers extérieurs à la base de données ou des BLOB/CLOB dans la base de données. Oracle excelle dans ce domaine et Exadata le rend extrêmement rapide et évolutif.
- RAG : permet d'utiliser au mieux les LLM et de minimiser leurs problèmes. Les LLM peuvent mentir (hallucinations), fournir des données obsolètes (limite d'entraînement) et ne connaître que les informations génériques issues de l'entraînement sur Internet. Oracle utilise des LLM préentraînés et des modèles d'intégration de vecteurs préentraînés pour effectuer les tâches difficiles. Oracle AI Vector Search utilise le vecteur généré par les modèles d'intégration de vecteurs et interagit avec les LLM.
Graphes de propriétés opérationnelles

Oracle Database offre une prise en charge native des structures de données de graphe de propriétés et des requêtes de graphe. Si vous recherchez de la flexibilité pour créer des graphes avec les données transactionnelles, JSON, Spatial et d'autres types de données, nous avons ce qu'il vous faut. Les développeurs peuvent désormais créer facilement des applications de graphes à l'aide du langage SQL, grâce à des outils et des structures de développement SQL existants.
Vidéos
- Création, interrogation et visualisation d'un graphe de propriétés avec SQL Oracle Database 23c Free—la version des développeurs (3:53)
- Intégration SQL des graphes de propriétés—Oracle CloudWorld 2022 (30:29)
Blogs
Articles
- Lucas Jellema : Graphe de propriétés SQL pour l'interrogation de style réseau
- Lucas Jellema : Exploration des bases de données relationnelles dans le style des bases de données de graphes avec des données sur la Formule 1 (contenu Github ici)
- Timothy Hall d'ACE : Graphes de propriétés SQL et SQL/PGQ dans Oracle Database 23c
Essayez-le
Documentation
-

Selon nous, le développement d'applications ne devrait pas être une tâche complexe et chronophage. Les dernières technologies d'IA générative nous donnent une excellente occasion de pousser encore plus loin la technologie AppDev low-code de pointe...
-

Pour clôturer 2023, voici un récapitulatif des nouvelles fonctionnalités d'Oracle Database 23c que nous avons mises en avant tout au long de l'année...
APEX apporte l'IA générative aux développeurs

Selon nous, le développement d'applications ne devrait pas être une tâche complexe et chronophage. Les dernières technologies d'IA générative nous donnent une excellente occasion de pousser encore plus loin la technologie AppDev low-code de pointe. Oracle APEX 24.1 repose sur trois piliers principaux de l'innovation qui vous permettent de créer facilement des applications professionnelles attrayantes : le développement d'applications assistées par l'IA, l'exploitation de la puissance de la plate-forme de données nouvelle génération d'Oracle et l'utilisation de puissants composants de niveau entreprise pour créer des applications cloud et mobiles évoluées.
Oracle APEX une fonctionnalité gratuite et entièrement pris en charge par Oracle Database et tous les services Oracle Database, notamment Oracle Autonomous Database, que les développeurs peuvent essayer gratuitement ici.
Vidéos
- Créez et gérez SQL en langage naturel à l'aide d'APEX AI Assistant (3:40)
- Optimisez la recherche sémantique avec Oracle APEX et AI Vector Search (2:15)
- Utilisez une copie de travail dans Oracle APEX pour suivre les modifications des applications (1:30)
Blogs
Essayez-le
- Créez une interface de questions-réponses innovante optimisée par l'IA générative avec Oracle APEX
- Créez une recherche d'images optimisée par l'IA dans votre application Oracle APEX
- Application intelligente de gestion de projet avec développement assisté par l'IA dans Oracle APEX
- Apprentissage : Oracle APEX : renforcer les applications low-code avec l'IA
Documentation
Joyeuses fêtes !

Pour clôturer 2023, voici un récapitulatif des nouvelles fonctionnalités d'Oracle Database 23c que nous avons mises en avant tout au long de l'année. Si vous n'avez pas encore essayé notre nouvelle version d'Oracle Database, en particulier si vous êtes développeur, consultez les différentes options ici ou sur oracle.com/fr/database/free.
Blogs
- Oracle Database 23c : la prochaine version de support à long terme
- Articles de blog sur Oracle Database 23c par SQLMaria
- Comment configurer Oracle Database 23c Free-Developer Release et ORDS sur OCI ?
- Oracle Database 23c Free—Developer Release : mise en route...
- Déploiement de la version pour les développeurs d'Oracle Database 23c Free sur Kubernetes avec Helm
- Explorer les vues de dualité relationnelle JSON dans Oracle Database 23c Free—Developer Release
Articles
Ateliers pratiques/Téléchargements
Documentation
-

Oracle Database 23c introduit un outil de migration en ligne qui simplifie la migration d'Oracle Advanced Queuing (AQ) vers Transactional Event Queues (TxEventQ) avec l'automatisation de l'orchestration, les diagnostics et la correction de compatibilité source et cible, ainsi qu'une expérience utilisateur unifiée...
-

Oracle continue d'étendre sa prise en charge des architectures natives du cloud et Kubernetes avec notre nouvel exportateur d'observabilité intégré dans Oracle Database...
-

Oracle Database 23c offre une compatibilité encore plus précise pour les applications Apache Kafka avec Oracle Database...
-

Les réservations sans verrouillage permettent de poursuivre les transactions simultanées sans être bloquées lors des mises à jour de lignes fortement actualisées. Les réservations sans verrouillage sont conservées sur les lignes au lieu d'être verrouillées...
-

Le framework Saga introduit dans Oracle Database 23c fournit une structure unifiée pour la création d'applications Saga asynchrones dans la base de données.
Outil de migration en ligne AQ vers TxEventQ

Oracle Database 23c introduit un outil de migration en ligne qui simplifie la migration d'Oracle Advanced Queuing (AQ) vers Transactional Event Queues (TxEventQ) avec l'automatisation de l'orchestration, les diagnostics et la correction de compatibilité source et cible, ainsi qu'une expérience utilisateur unifiée. Les scénarios de migration peuvent être de courte ou de longue durée et être réalisés avec ou sans interruption de service AQ, éliminant ainsi toute perturbation opérationnelle.
Les clients AQ existants intéressés par des files d'attente de débit plus élevées et compatibles Kafka utilisant un client Java Kafka et des API REST de type Confluent peuvent facilement migrer d'AQ vers TxEventQ. TxEventQ offre une évolutivité, des performances, un partitionnement basé sur des clés et une prise en charge native des données JSON, ce qui facilite l'écriture d'applications/de microservices orientés événements dans plusieurs langages, notamment Java, JavaScript, PL/SQL, Python, etc.
Blogs
API Kafka

Oracle Database 23c offre une compatibilité encore plus précise pour les applications Apache Kafka avec Oracle Database. Cette nouvelle fonctionnalité facilite la migration des applications Java Kafka vers les files d'attente d'événements transactionnels (TxEventQ). Les API Java Kafka peuvent désormais se connecter au serveur Oracle Database et utiliser TxEventQ comme plateforme de messagerie.
Les développeurs peuvent facilement migrer une application Java existante qui utilise Kafka vers Oracle Database à l'aide du pilote JDBC. De plus, avec la fonctionnalité de bibliothèque côté client d'Oracle Database 23c, les applications Kafka peuvent désormais se connecter à Oracle Database au lieu d'un cluster Kafka et utiliser simplement la plateforme de messagerie de TxEventQ.
Essayez-le
Articles
Blogs
- Nouvelle version 23c des API Java compatibles avec Kafka pour les files d'attente d'événements transactionnelles publiées
- Explorer Kafka Java Client for TxEventQ — créer le plus simple des producteurs et des consommateurs
- Oracle REST Data Services 22.3 apporte de nouvelles API REST pour la mise en file d'attente des événements transactionnels
Documentation
- Interopérabilité de la file d'attente des événements transactionnels avec Apache Kafka (API Java)
- Interface client Java Kafka pour Oracle Transactional Event Queues (API Java)
- Client Java Kafka pour Oracle Transactional Event Queues (API Java)
- Connecteurs Kafka pour TxEventQ (Connecteurs)
- Oracle Transactional Event Queues REST Endpoints (API REST)
Réservations de valeur de colonne sans verrouillage

Les réservations sans verrouillage permettent de poursuivre les transactions simultanées sans être bloquées lors des mises à jour de lignes fortement actualisées. Les réservations sans verrouillage sont conservées sur les lignes au lieu d'être verrouillées. Elles vérifient si les mises à jour peuvent aboutir et diffèrent les mises à jour jusqu'à l'heure de validation de la transaction. Les réservations sans verrouillage améliorent l'expérience utilisateur et la simultanéité dans les transactions.
Vidéos
Blogs
Observabilité de Grafana

Oracle continue d'étendre sa prise en charge native du cloud et de Kubernetes avec notre nouvel outil Observability Exporter pour Oracle Database. Il permet aux clients d'exporter facilement des indicateurs de base de données et d'application au format standardisé Prometheus, et de créer facilement des tableaux de bord Grafana pour surveiller les performances de leurs bases de données et applications Oracle.
API Saga dans Oracle Database 23c

Le framework Saga introduit dans Oracle Database 23c fournit une structure unifiée pour la création d'applications Saga asynchrones dans la base de données. Saga rend le développement d'applications de microservices modernes et hautes performances plus facile et plus fiable.
Une Saga est une transaction commerciale couvrant plusieurs bases de données, implémentée comme une série de transactions locales indépendantes. Les Sagas évitent le verrouillage global des transactions distribuées synchrones et simplifient les exigences de cohérence pour maintenir un état global de l'application. Le framework Saga s'intègre aux colonnes réservables sans verrouillage dans Oracle Database 23c pour fournir une compensation automatique Saga, ce qui simplifie le développement d'applications.
Le framework Saga émule la spécification MicroProfile LRA.